mathematicsnumerical-methods
econometrics.blog
econometricseconomics
econometricseconomics
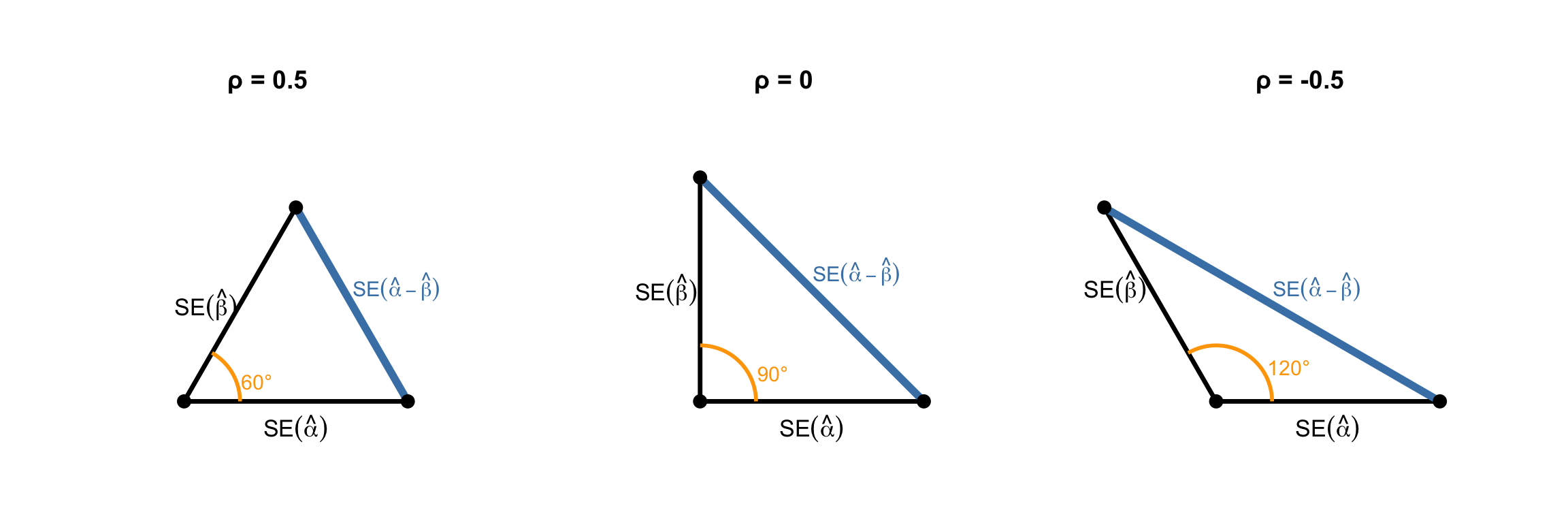
mathematicsstatistics
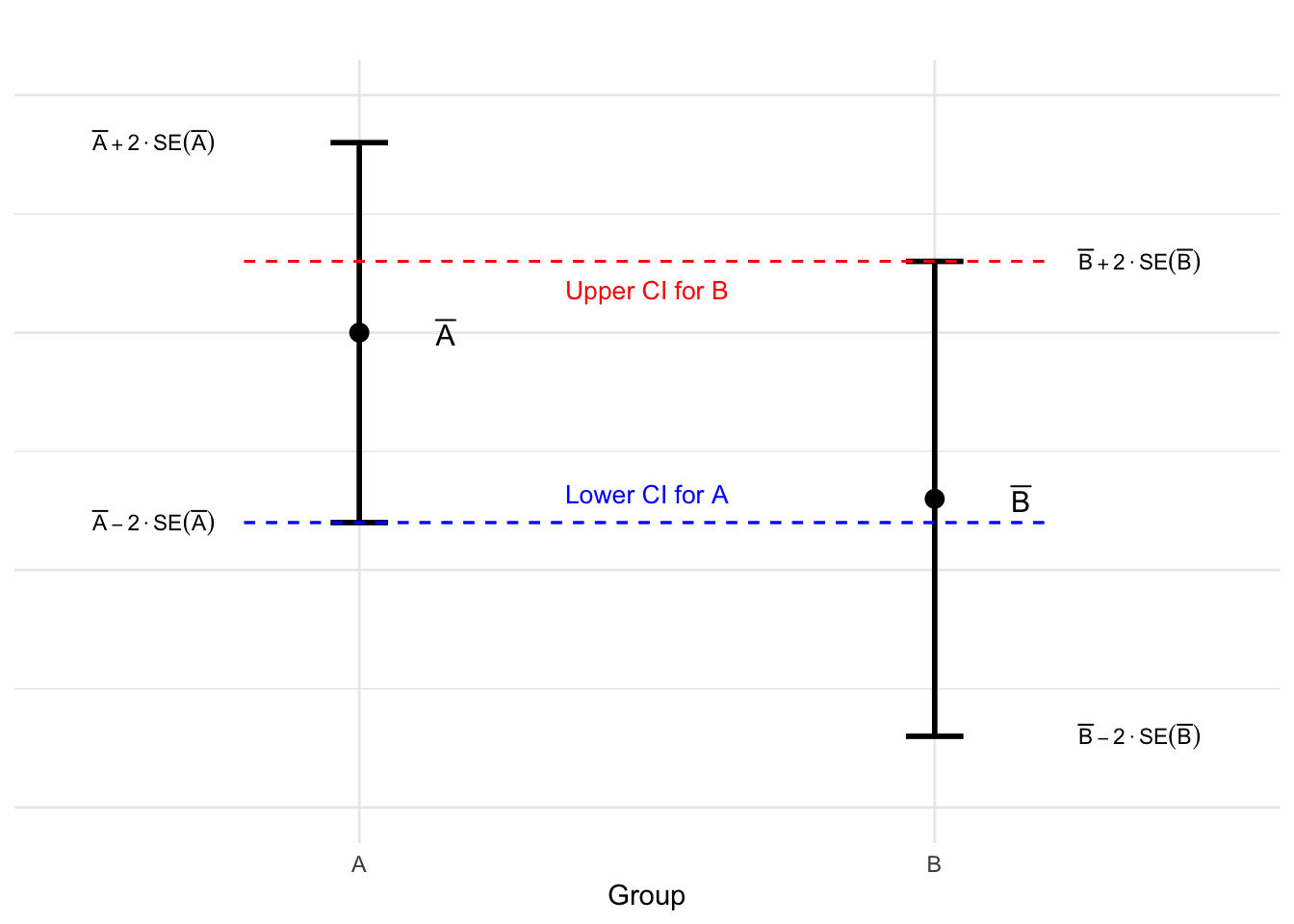
mathematicsstatistics
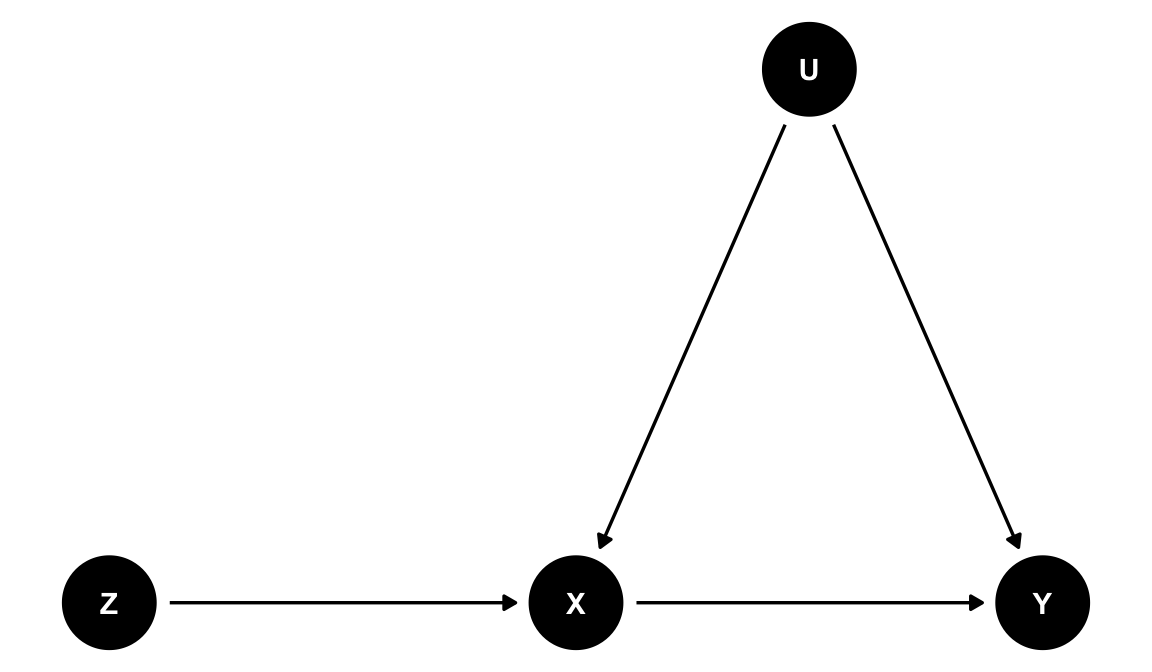
behavioral-economicseconomics
econometricseconomics
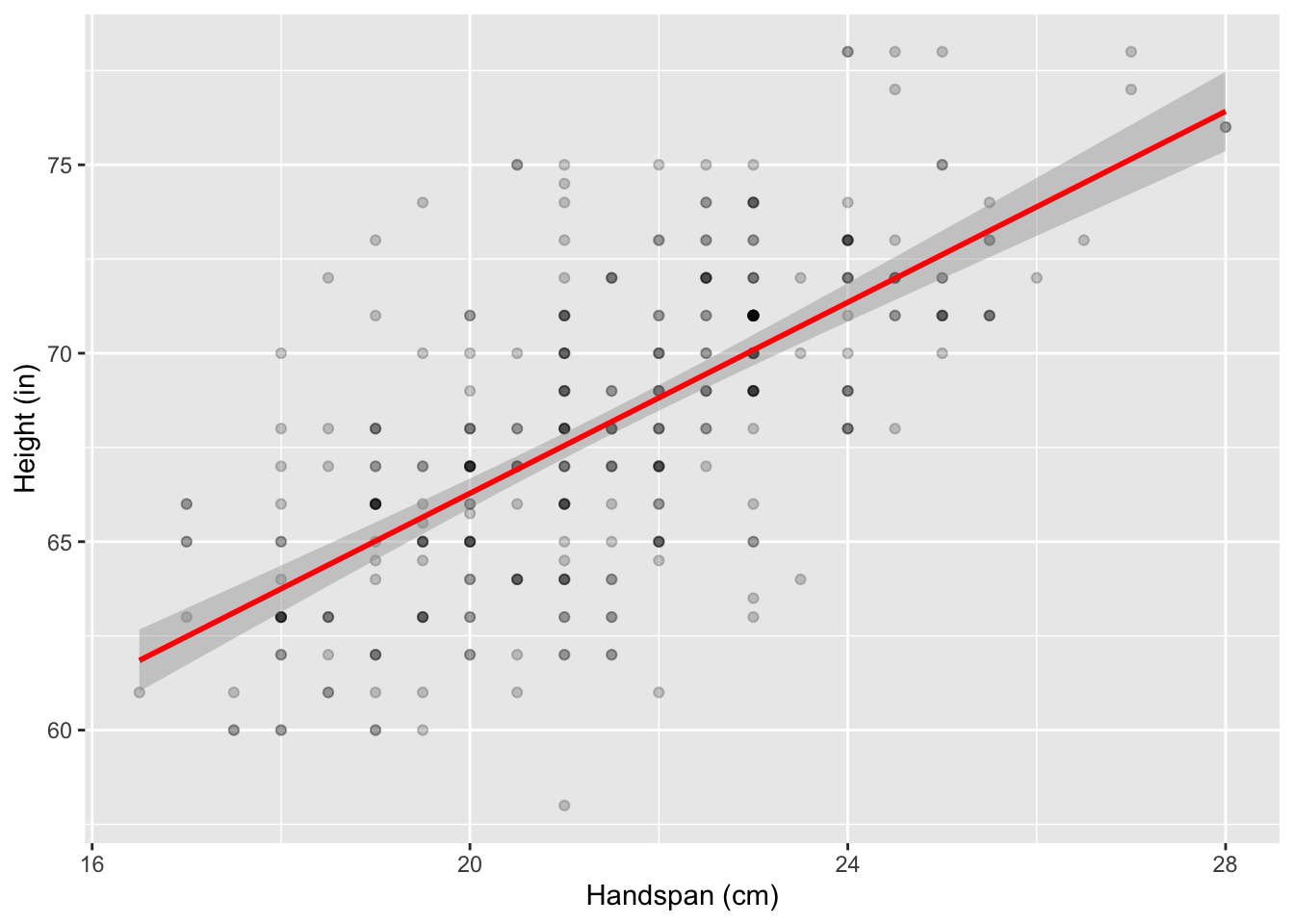
econometricseconomics
econometricseconomics
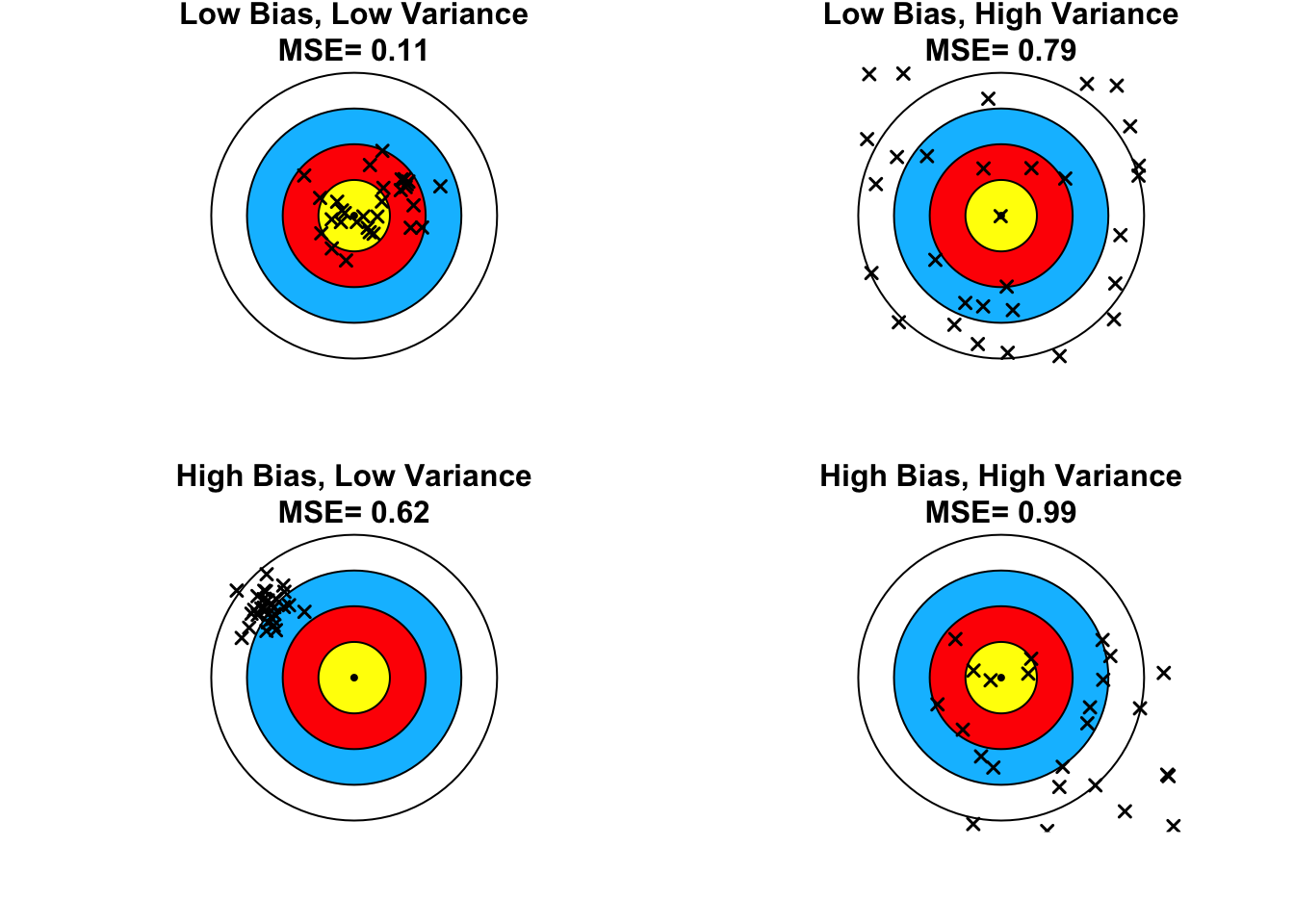
econometricseconomicsmathematicsstatistics
diagnosticsmedicine
econometricseconomics
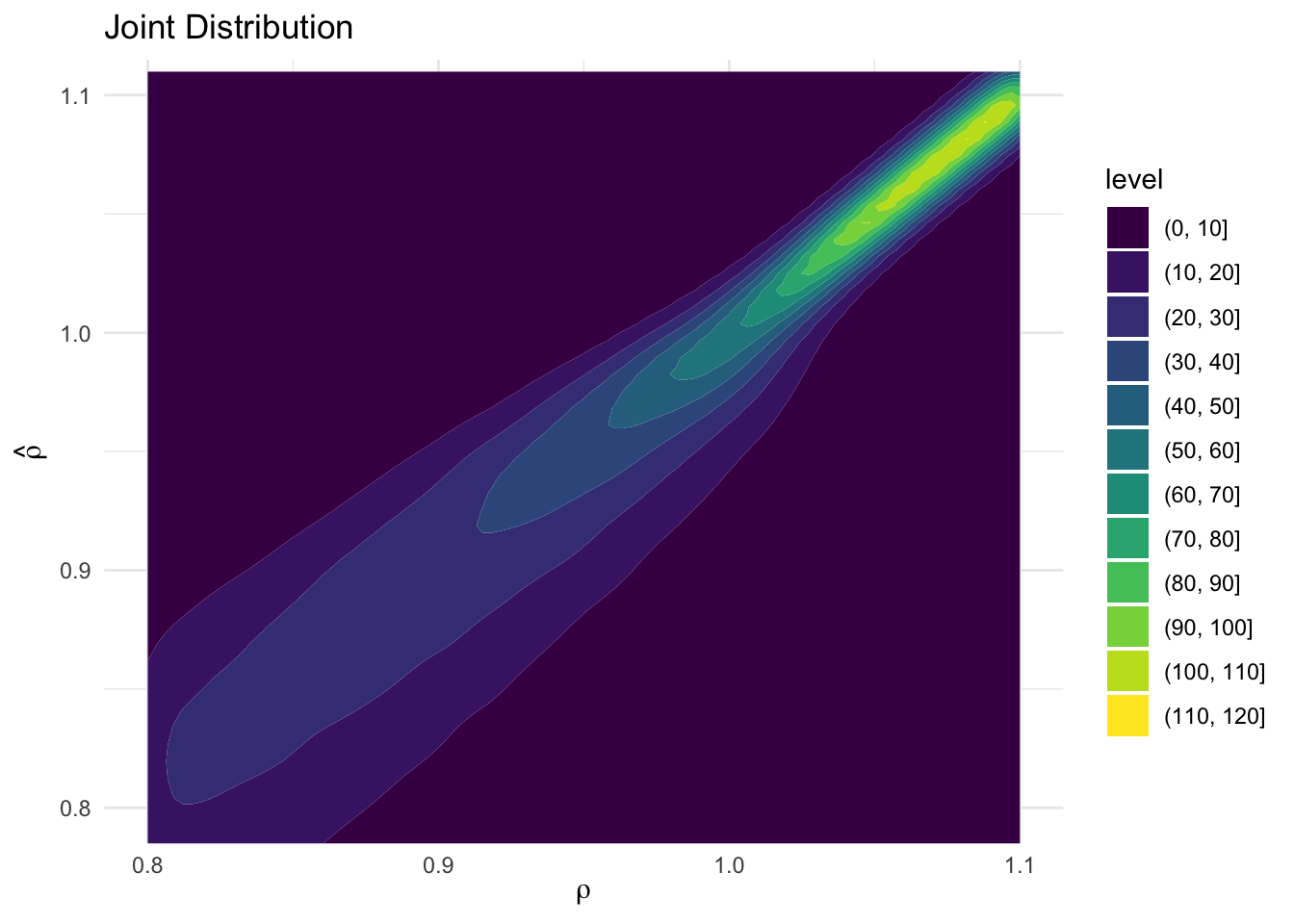
econometricseconomics
econometricseconomics
mathematicsstatistics
mathematicsstatistics
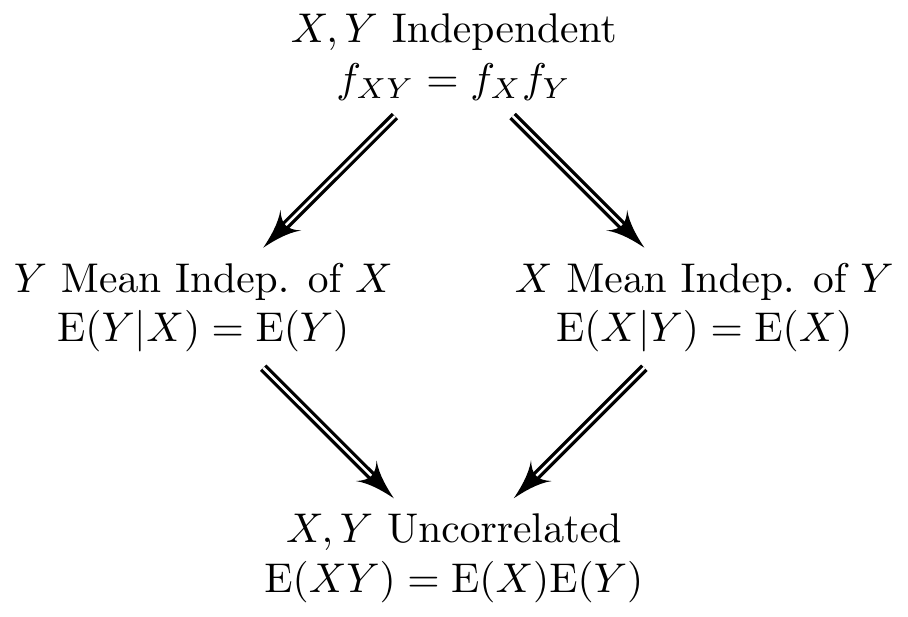
econometricseconomics
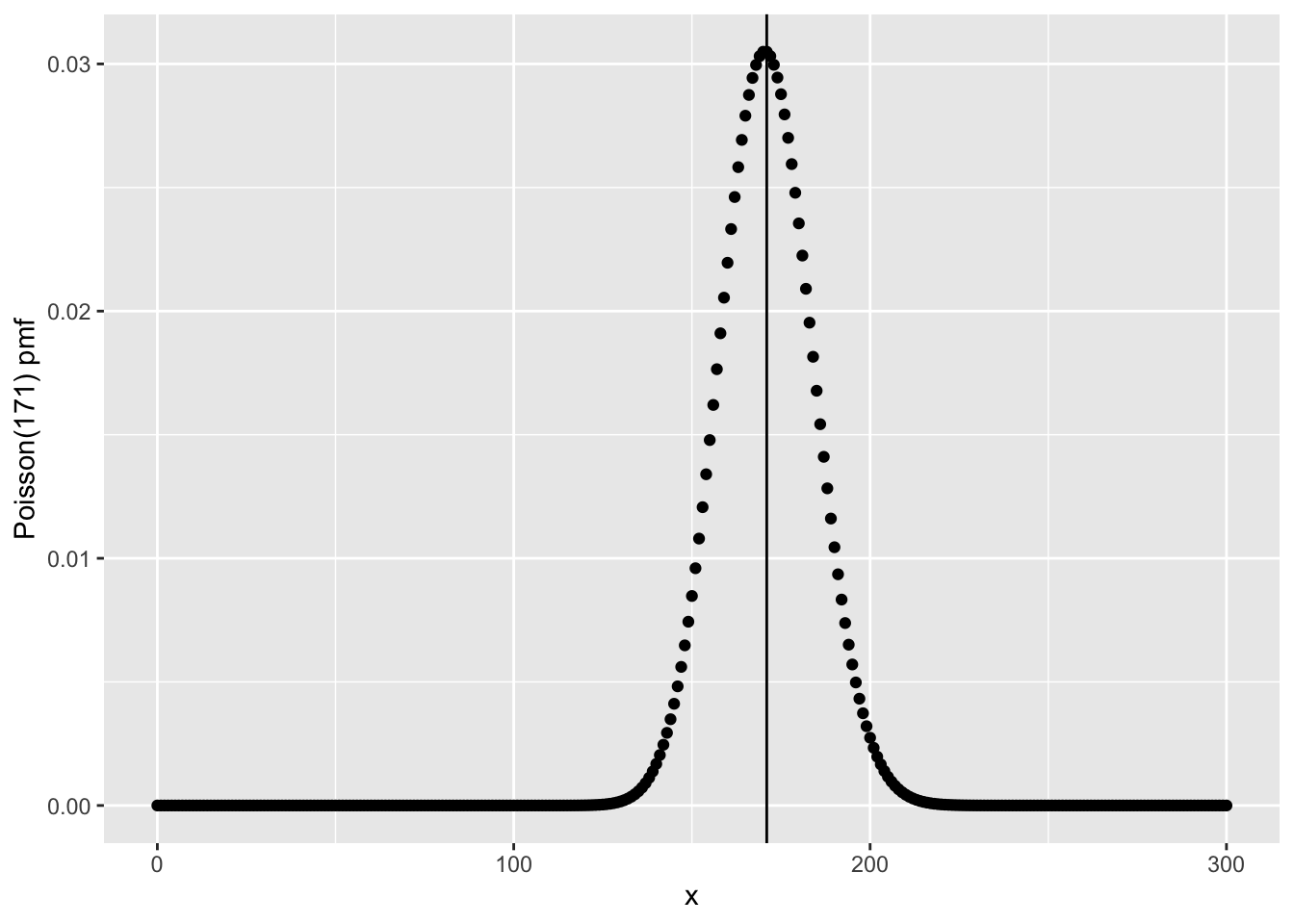
mathematicsprobability
Sign up to keep scrolling
Create your feed subscriptions, save articles, keep scrolling.
Already have an account?