
"Codex took 6 hours to implement this seemingly simple refactor". "I think Research mode on Perplexity is stuck." We all know LLM APIs are slow, and are content with staring at a spinner while the model slowly emits tokens. But what happens when you're building AI agents that need to be low latency? We hit this while building FixBugs , an AI debugging agent that reads bug reports, logs, code, screenshots, traces, and issue comments, then reproduces the bug and finally generates a validated fix.
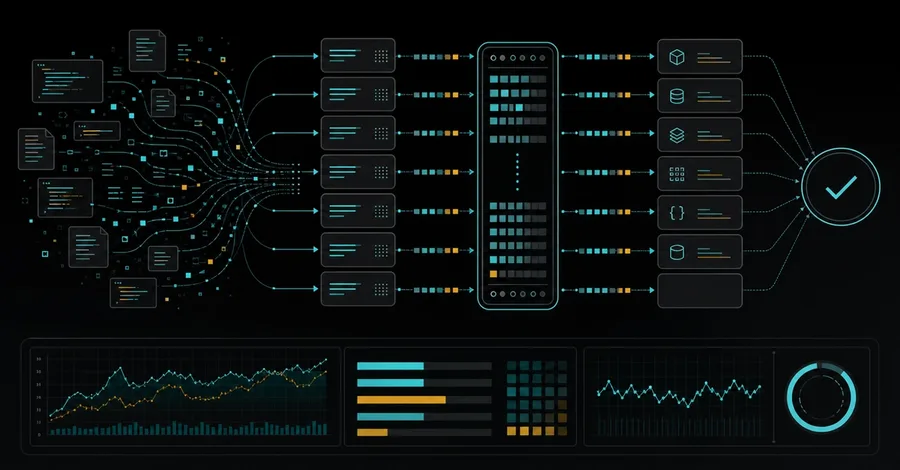
High-performance AI agents are distributed systems
Kirti Rathore