
If you run vLLM, Triton, or any other inference server on Kubernetes, you have probably noticed that the HPA cannot see the GPU. Autoscaling decisions are driven by CPU and memory, while the resource that actually determines inference capacity remains invisible. A CNCF blog post published in May 2026 describes how to fix this by building a KEDA external scaler. The problem with default autoscaling The Kubernetes Horizontal Pod Autoscaler (HPA) was designed to scale on CPU and memory metrics. For
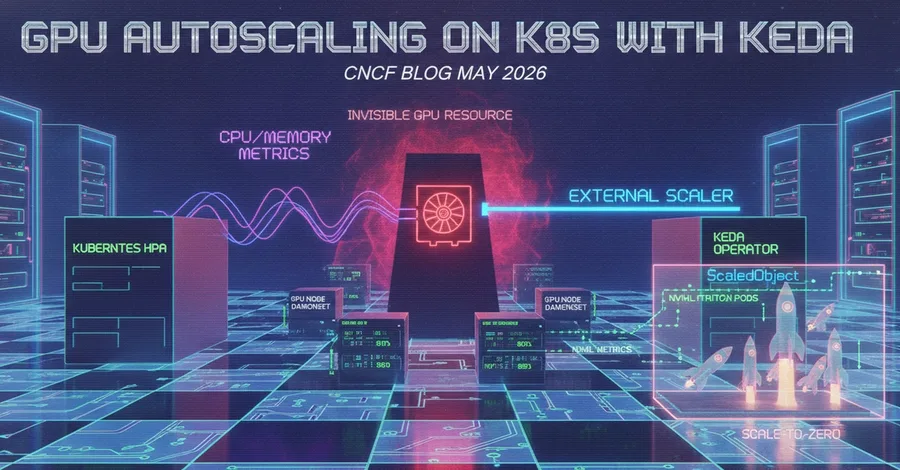
GPU autoscaling on Kubernetes with KEDA: building an external scaler with NVML
Bruno Santos