aideep-learningmachine-learning
Count Bayesie - A Probability Blog
mathematicsprobability
aimachine-learning
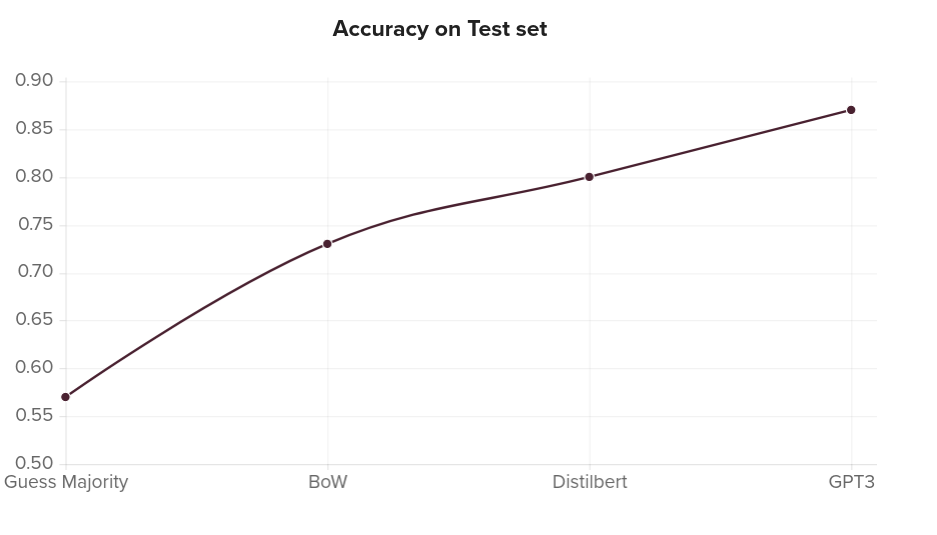
aimachine-learning

mathematicsprobability
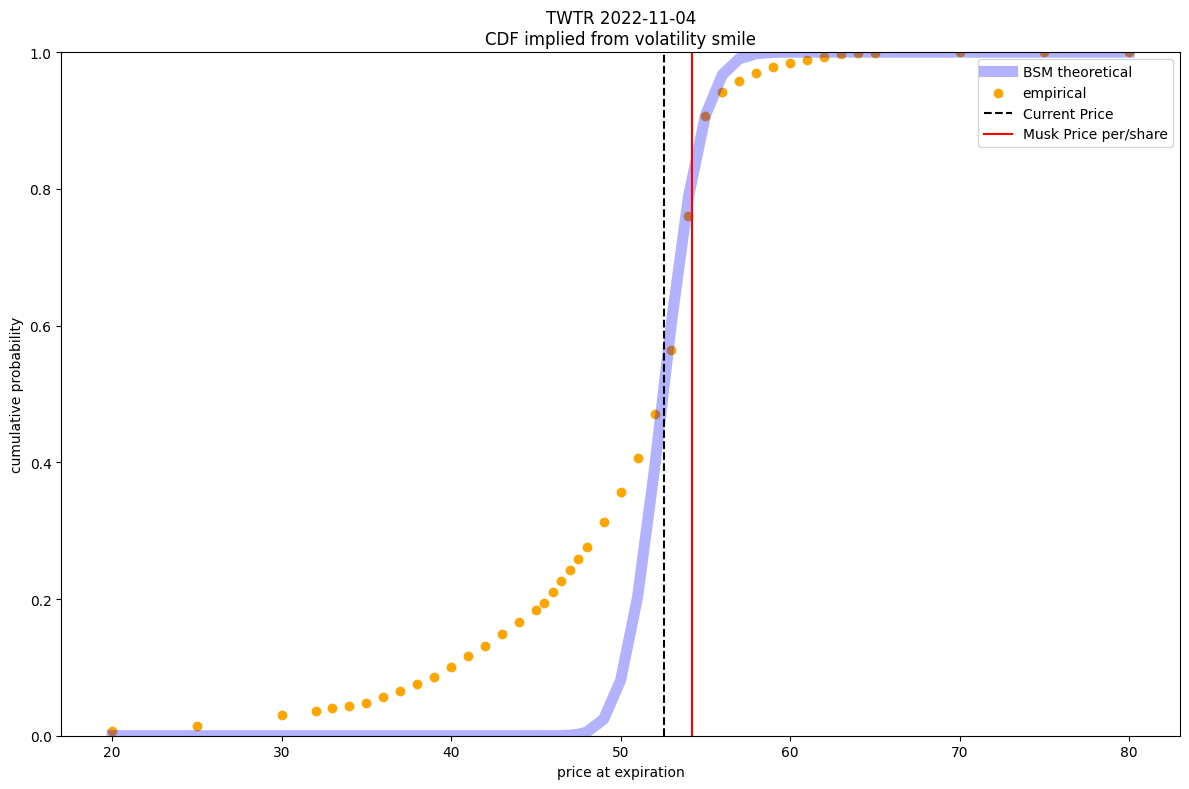
market-microstructurequant-financerisk-management

mathematicsstatistics
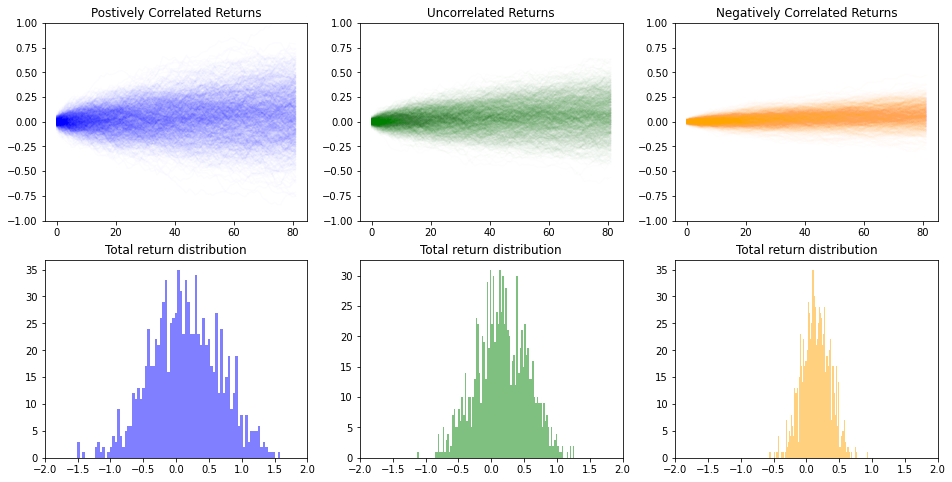
optimizationportfolio-theoryquant-finance
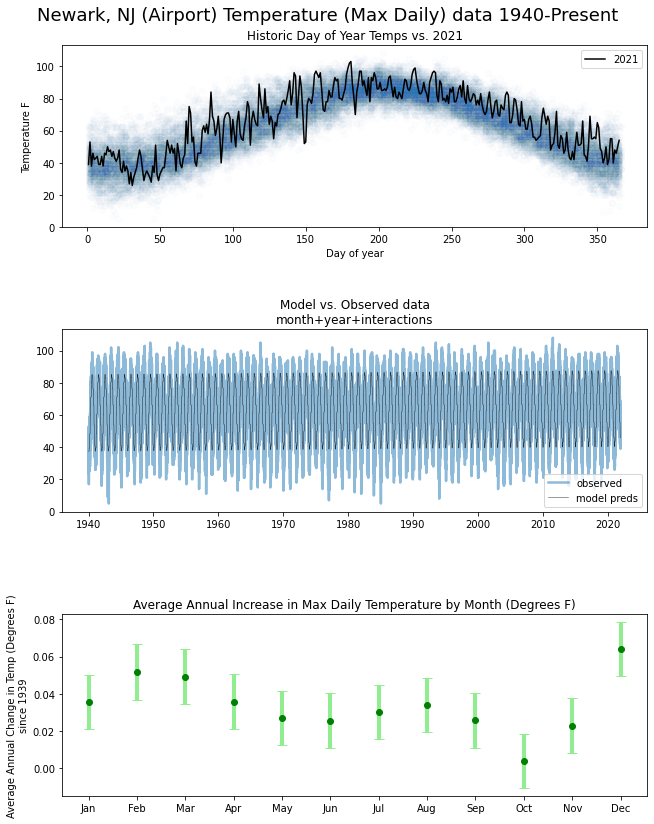
earth-sciencemeteorology
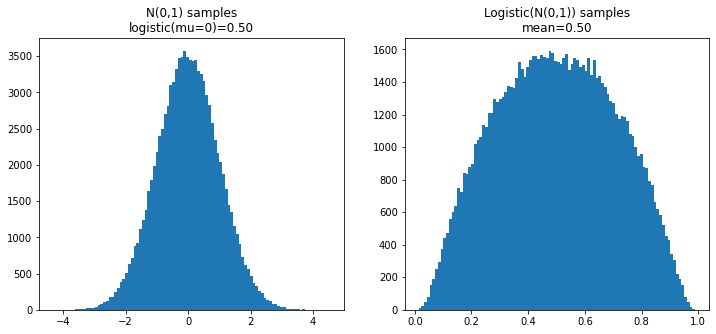
mathematicsstatistics
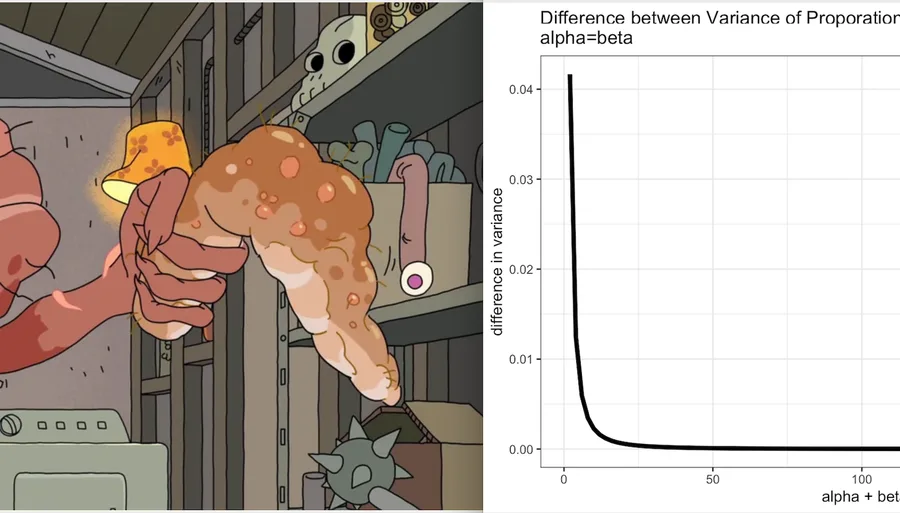
mathematicsstatistics
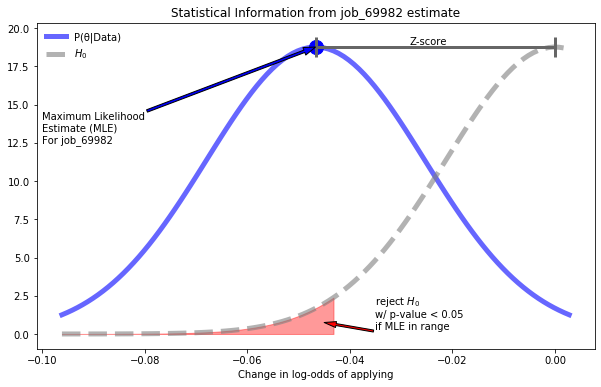
mathematicsstatistics
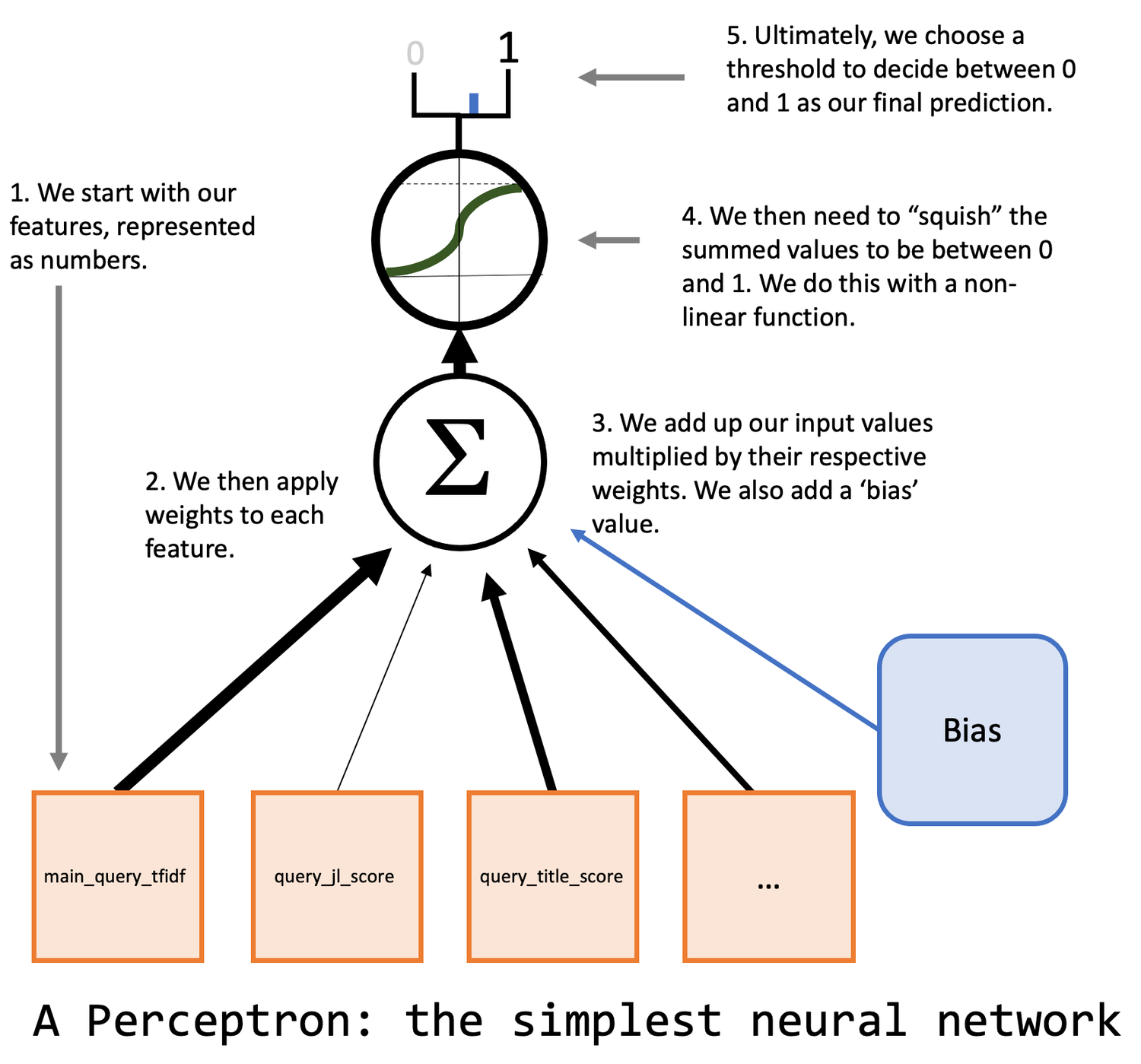
aimachine-learning
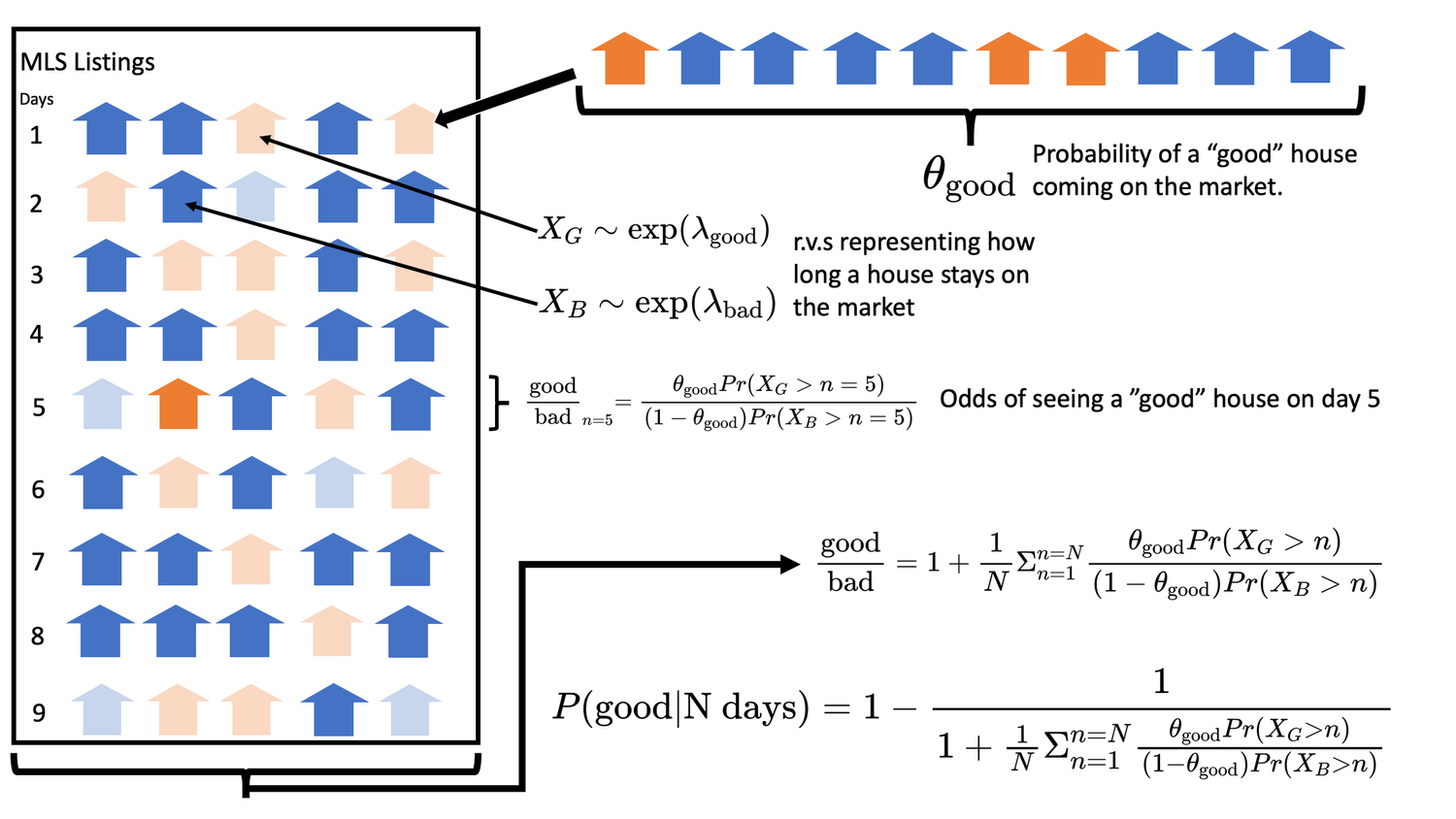
mathematicsstatistics
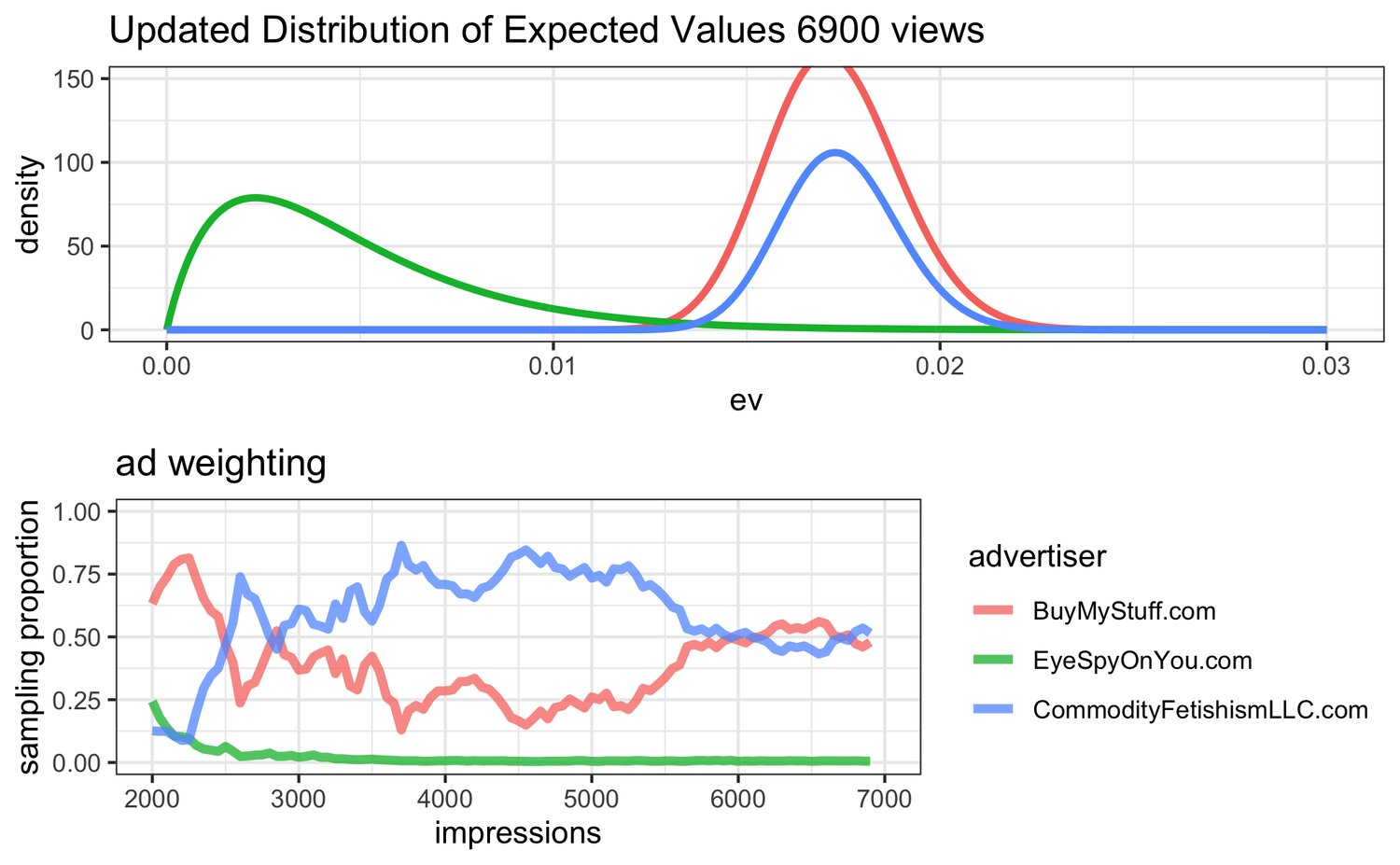
aimachine-learning
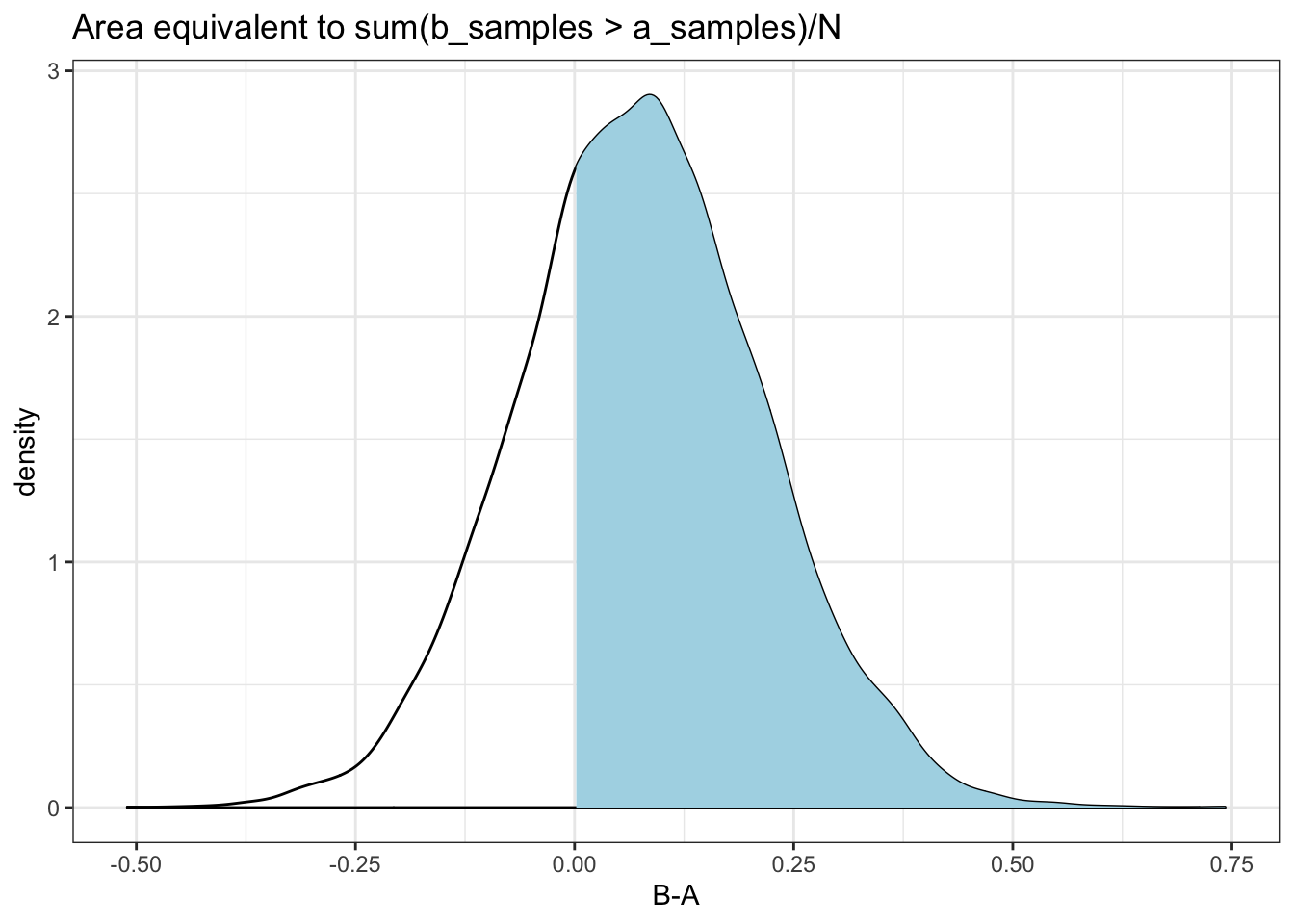
mathematicsstatistics
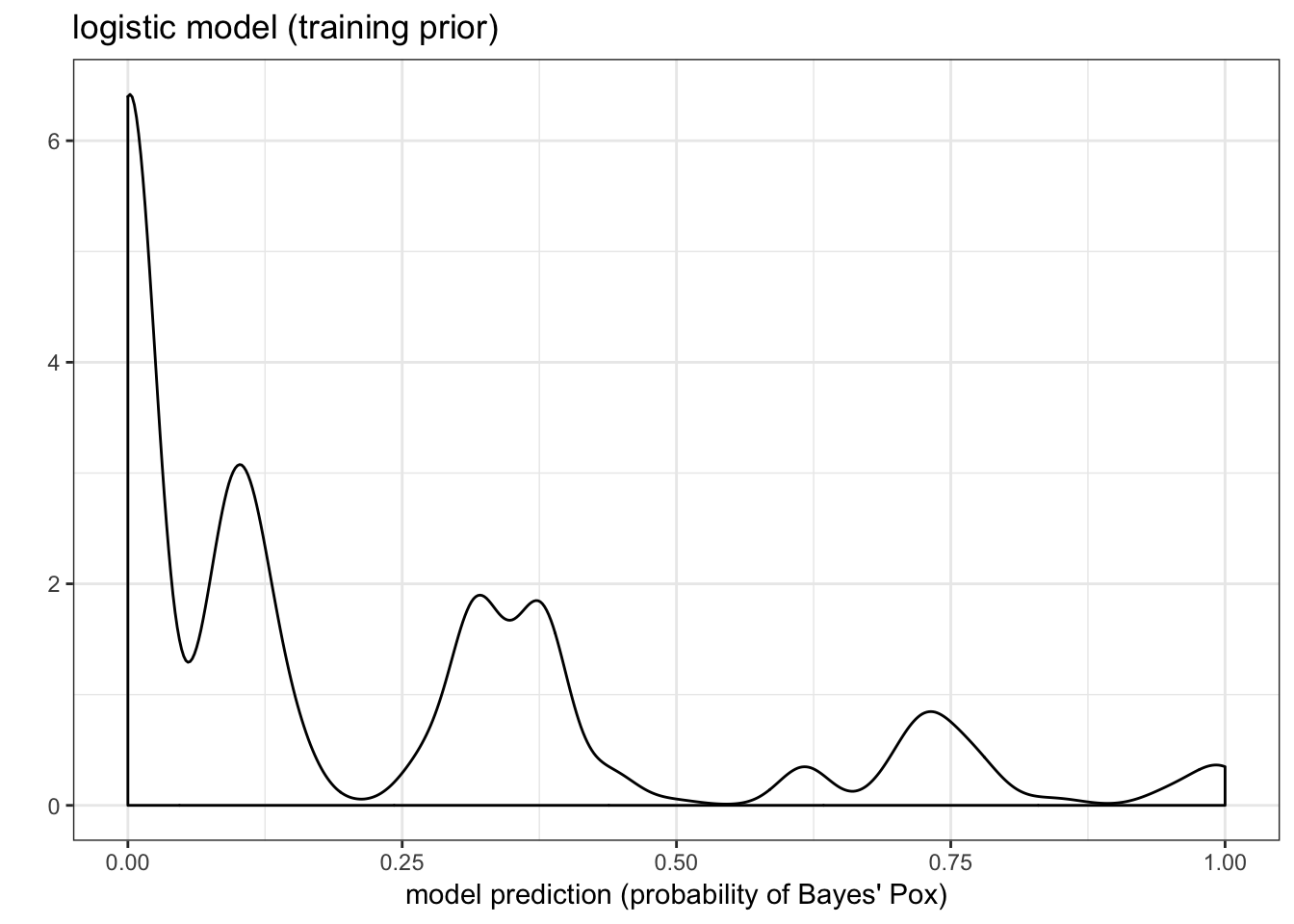
mathematicsstatistics
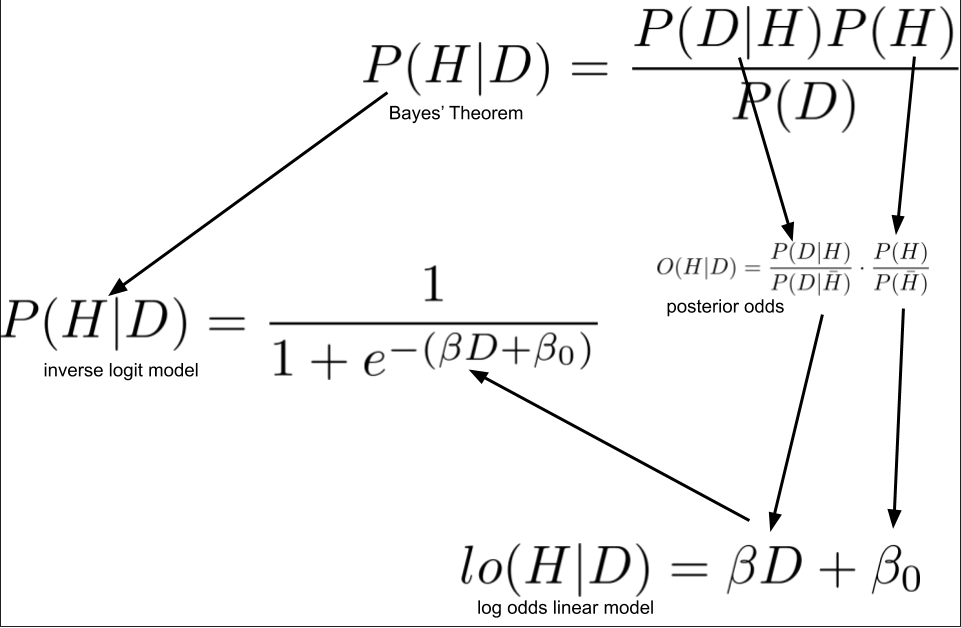
aimachine-learning
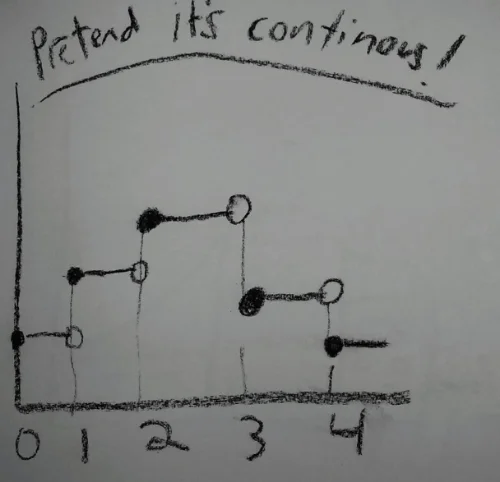
mathematicsprobability

mathematicsmeasure-theoryprobability
Sign up to keep scrolling
Create your feed subscriptions, save articles, keep scrolling.
Already have an account?