
I saw a developer asking on Reddit if there was any “sane way” to manage Cloud Run cold starts for AI across multiple regions. They were experiencing startup latencies of up to 20 seconds, a frustrating gap where the infrastructure is spinning up while the user waits for a response. The discussion was full of developers who had almost given up on serverless GPUs, with some even migrating back to GKE just to escape the latency. I decided it was time to dive deep into the Mechanics of AI Cold Star
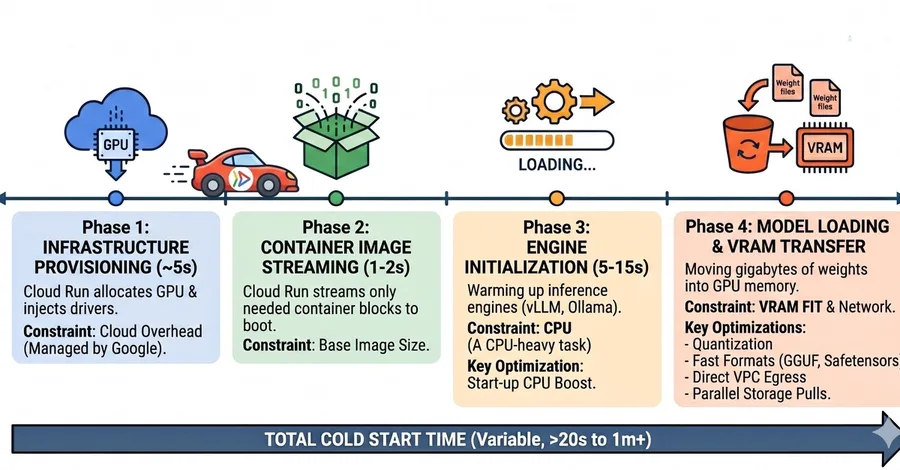
A Guide to AI Cold Starts on Cloud Run
Shir Meir Lador