
Vision-language-action models are the current state of the art in robotic manipulation. They still cannot pick up a potato chip without crushing it. That is the result published earlier this year by the team behind the Video Tactile Action Model (VTAM). On a potato chip pick-and-place task — a task that demands high-fidelity force awareness, where vision alone cannot distinguish a crushing grasp from a holding one — VTAM outperformed the π0.5 baseline by 80%. Across the broader contact-rich benc
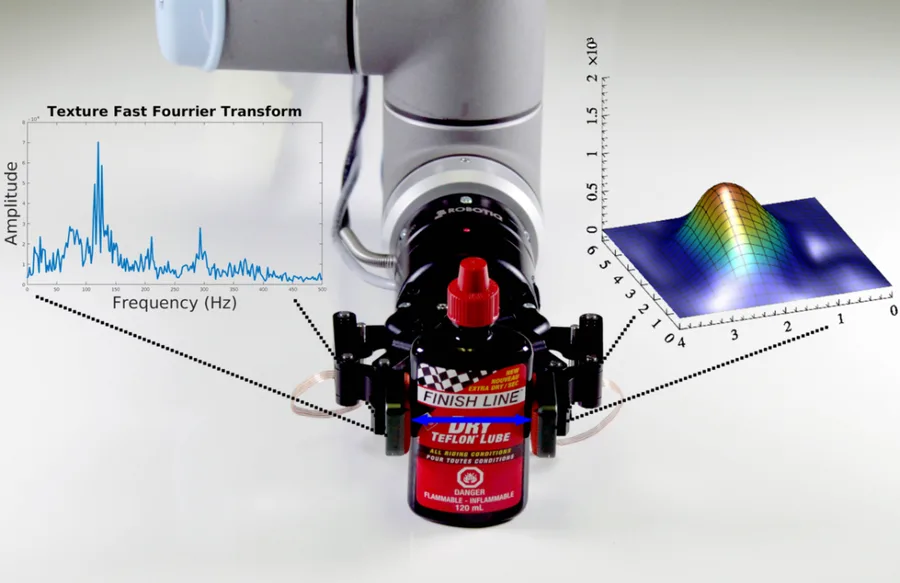
How tactile sensing improves model performance
Jennifer Kwiatkowski