
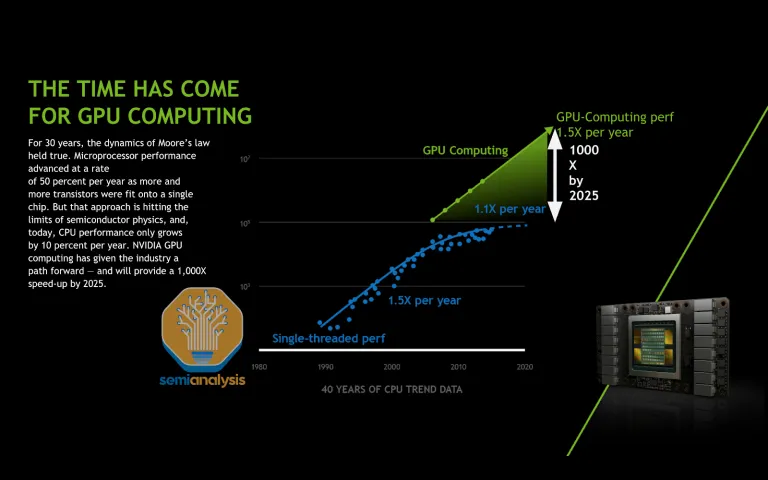
In our AI Scaling Laws article from late last year, we discussed how multiple stacks of AI scaling laws have continued to drive the AI industry forward, enabling greater than Moore’s Law growth in model capabilities as well as a commensurately rapid reduction in unit token costs. These scaling laws are driven by training and […]
NVIDIA Tensor Core Evolution: From Volta To Blackwell
Dylan Patel