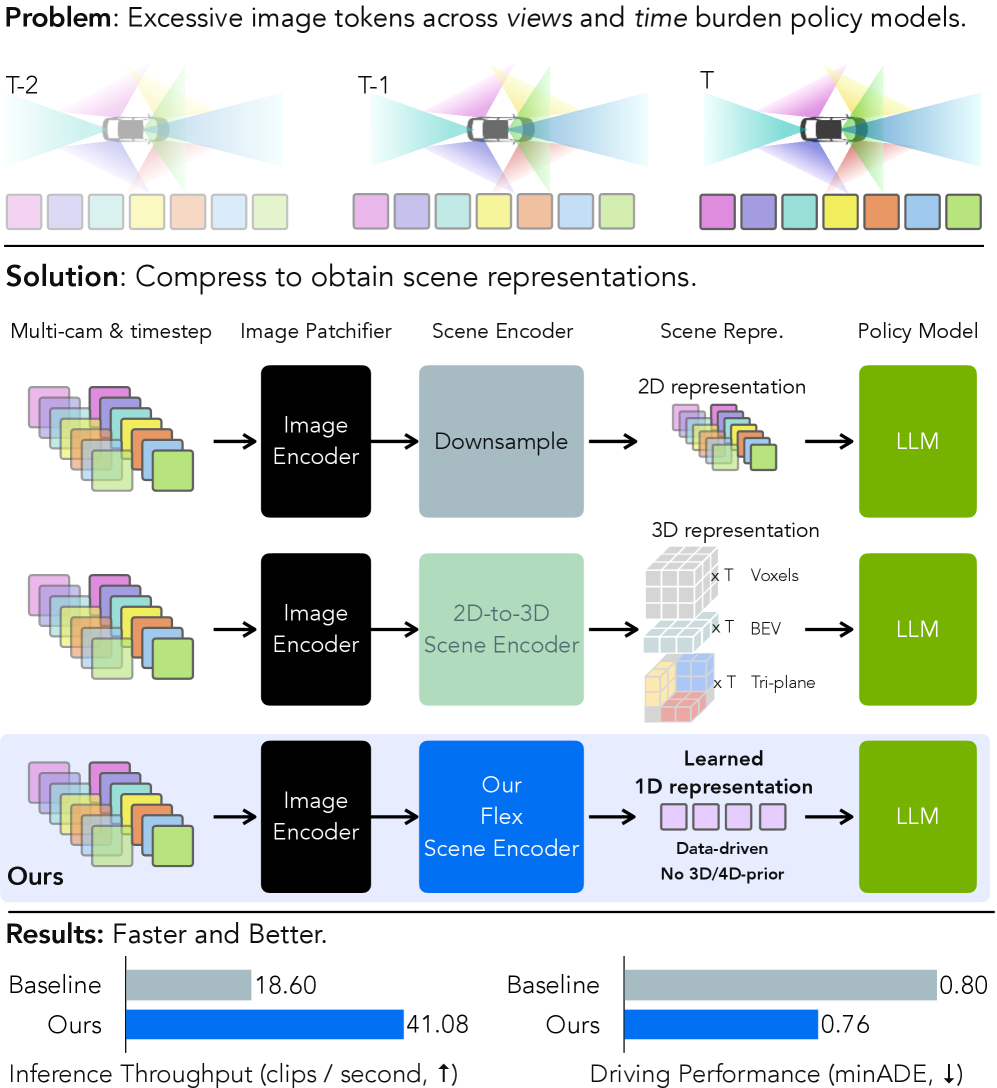
We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as...