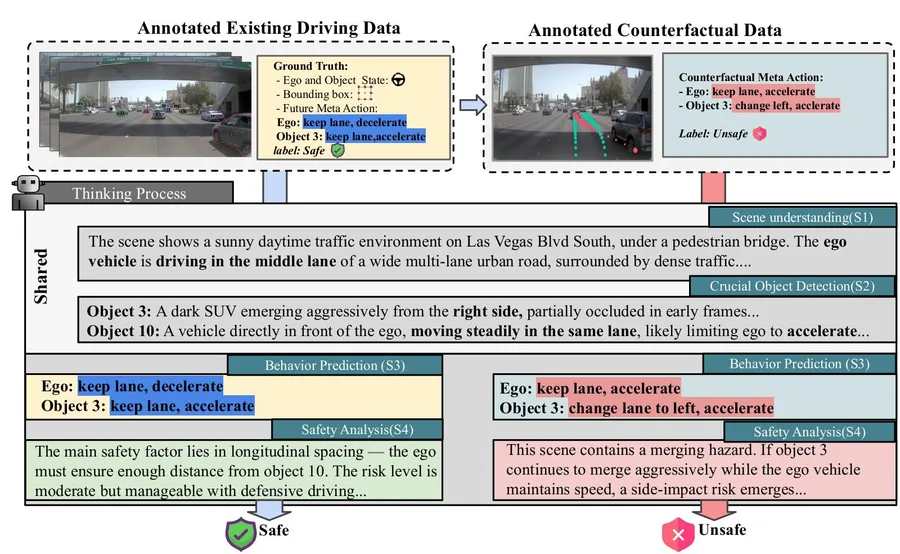
Safety remains a fundamental challenge in autonomous driving, with a key step being the development of a safety evaluator that can reliably identify unsafe (i.e., collision-prone) scenarios. Existing methods, however, either rely heavily on object trajectories or use only language-based reasoning, neglecting crucial visual cues and limiting their generalization to unsafe events. Vision–Language Models (VLMs) have recently shown strong generalization across various autonomous driving tasks, yet..